Benchmarking NVIDIA P100 for Compute Bound Performance in Echelon Software
There is a vast and growing performance gap between Intel Xeon chips and NVIDIA GPUs for both memory bound and compute bound kernels.

There is a vast and growing performance gap between Intel Xeon chips and NVIDIA GPUs for both memory bound and compute bound kernels.
Previously I posted NVIDIA P100 performance results for full ECHELON software runs which are dominated by memory bound kernels.
Below I'm showing fresh P100 results for compositional flash, one of the few compute bound kernels found in reservoir simulators. For this chart the reference SPE3 problem is solved using a 10 component flash calculation on 1 million pressure-temperature points. Platforms considered are an 8 core Intel Haswell E5-2630v3 and the Fermi GF200, Kepler GK210 and new Pascal P100 chips from NVIDIA. Performance results are normalized to Haswell=1.0.
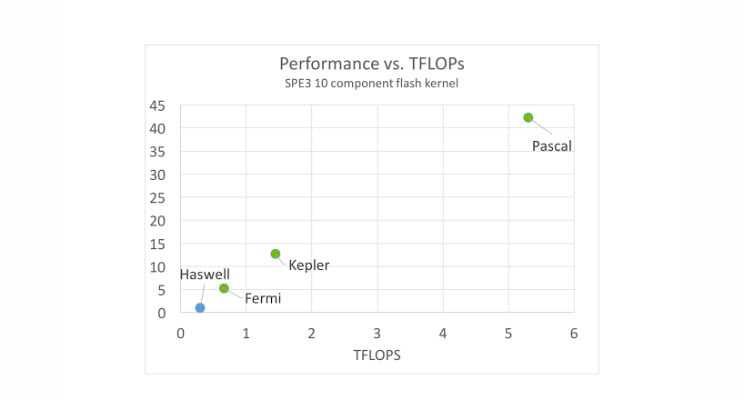
Our single-core CPU results compare very closely, both in accuracy and performance, to the highly-optimized results published by Haugen and Beckner from ExxonMobil. Here, however, we improve upon Haugen and Beckner with a multi-threaded parallel implementation. Three conclusions: i) P100 is 42x faster than the 8 core Intel Xeon Haswell chip ii) performance per TFLOP is about 2.5x better on GPU than CPU and iii) GPU performance again scales in a beautiful linear manner with TFLOPs. In summary there is a vast and growing performance gap between Intel Xeon chips and NVIDIA GPUs for both memory bound and compute bound kernels. This is great news for those interested in bringing game-changing capability to reservoir simulation software tools.

Vincent Natoli
Vincent Natoli is the president and founder of Stone Ridge Technology. He is a computational physicist with 30 years experience in the field of high-performance computing. He holds Bachelors and Masters degrees from MIT, a PhD in Physics from the University of Illinois Urbana-Champaign and a Masters in Technology Management from the Wharton School at the University of Pennsylvania.
