GPU-based Reservoir Simulation: ECHELON 2.0 Software Compositional Performance Characteristics
ECHELON's GPU-based performance sets a new bar for reservoir simulation software by drastically decreasing compositional model runtimes.

ECHELON's GPU-based performance sets a new bar for reservoir simulation software by drastically decreasing compositional model runtimes.
Posted in: ECHELON Software
ECHELON 2.0 is the most significant release of Stone Ridge Technology's (SRT's) petroleum reservoir simulation software since we introduced it to the industry in 2016. One of its key features is compositional formulation which was planned, designed, implemented and rigorously tested over the last several years by our team at SRT and our colleagues at Eni. As with our black oil design, which has set the bar for industry performance, our compositional formulation was created from inception to make full use of the GPU’s capabilities and resources, optimizing for memory bandwidth, storage and FLOPS. We did not start with a multi-core CPU implementation and shoe-horn it into a GPU. The difference is apparent in at least three significant areas, performance, memory footprint and scaling. With the release of ECHELON 2.0 we deliver the industry’s first compositional simulator fully formulated from the ground up to run on GPUs.
The commercial release contains support for both the fully implicit (FIM) and adaptive implicit methods (AIM). The latter improves performance for some models and reduces GPU memory requirements in all cases. The ECHELON 2.0 code base has been extensively validated and hardened on numerous models ranging from simple synthetic cases designed to exercise particular aspects of the formulation, to full-field assets with hundreds of wells, advanced features, and complex recovery strategies. Our custom solver methodology has proven to be robust and extremely efficient. The careful use of GPU memory and bandwidth allows large compositional models to be run quickly, often on a single GPU, setting us apart from our competitors in the industry. Benchmarking has shown that the advantage of our formulation actually grows with increasing component count, making it practical to employ more accurate fluid descriptions with minimal increase in runtime. In this short blog we will present results from several synthetic models to highlight key aspects of ECHELON's compositional capability.
The best and most compelling way to evaluate ECHELON’s performance is to request a trial license and test on real assets relevant to your organization. ECHELON reservoir simulation software is compatible with ECLIPSE standard input decks so most often no modifications are needed to begin testing. Input and output files are easily created, analyzed and visualized using the tools currently employed by the industry. For this blog we will present data on synthetic models that were created to test and benchmark the simulator. The first model considered, shown in Figure 1, is a greenfield sandstone reservoir with permeability values ranging from 0.1 to 100 md and porosity ranging from 6 to 20%. It has 569K cells, 9 components, and 50 wells, 40 of which are producers. The forecast goes out 20 years. This model was run on a single NVIDIA V100 GPU using fully implicit method (FIM) and completes in about 11 minutes.
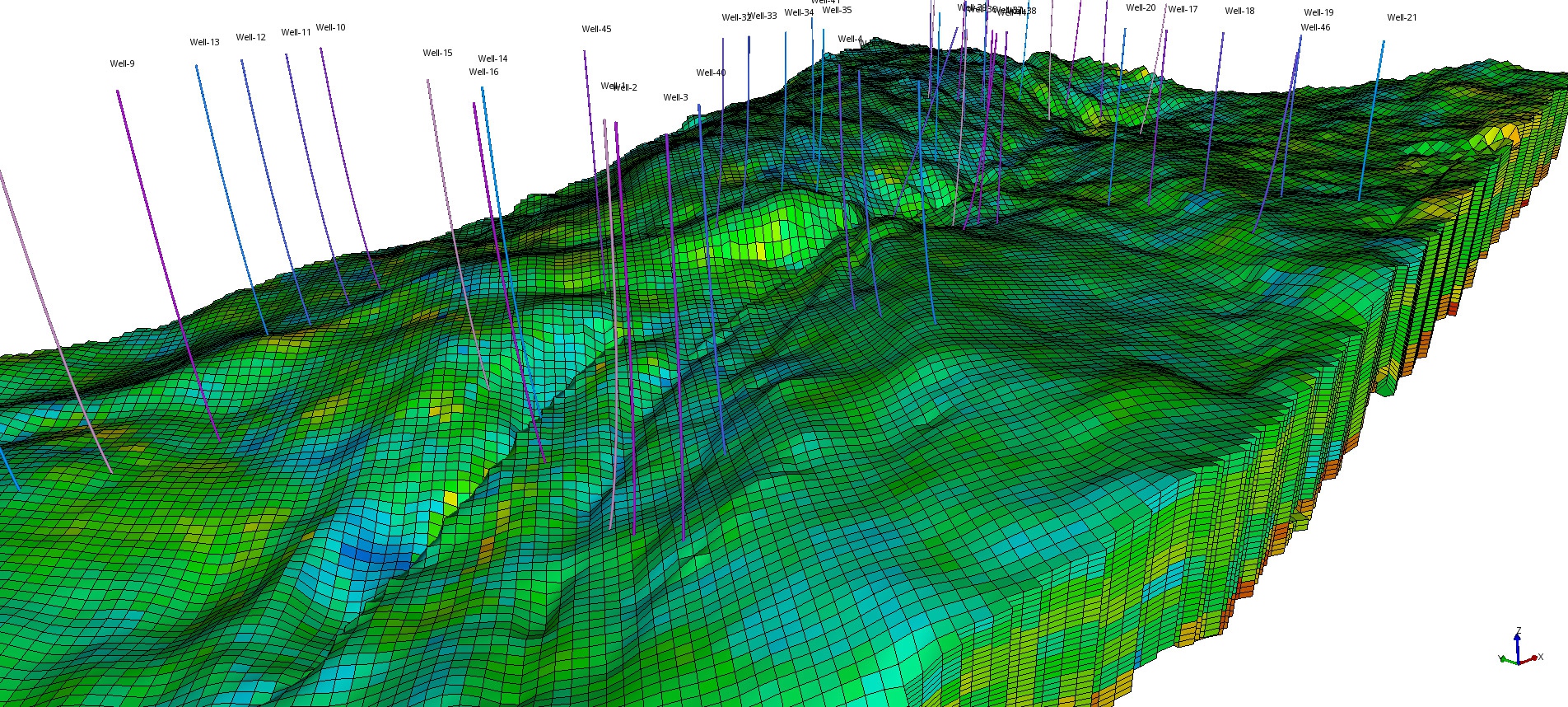
Figure 1 - Synthetic greenfield sandstone model with 569K cells.
A challenging example used to demonstrate ECHELON software's performance capabilities on compositional models concerned the deployment of drilling strategies in geologically complex reservoirs. In this case, the model is a tight oil reservoir with permeabilities ranging from 10 to 200 md with high water saturation. The model has 11.2 million active cells and 9 components. The objective was to define drilling targets for 100 new well locations. The simulation was performed using a fully implicit method (FIM) and a high-resolution geological model.

Figure 2 - Reservoir model showing the depth as a grid property.
ECHELON reservoir simulation software completed 20 years of forecasting in just 30 minutes using 8 NVIDIA A100 GPUs. Using 4 NVIDIA A100 GPUs the model completes in 45 minutes (Figure 3). A total of 4 cases with different numbers of GPUs (1, 2, 4 and 8 GPUs) were simulated, all showing consistent physical results and solid numerical stability (e.g. nearly constant number of newton and linear iterations). ECHELON shows consistent behavior from 1 to 8 GPUs.
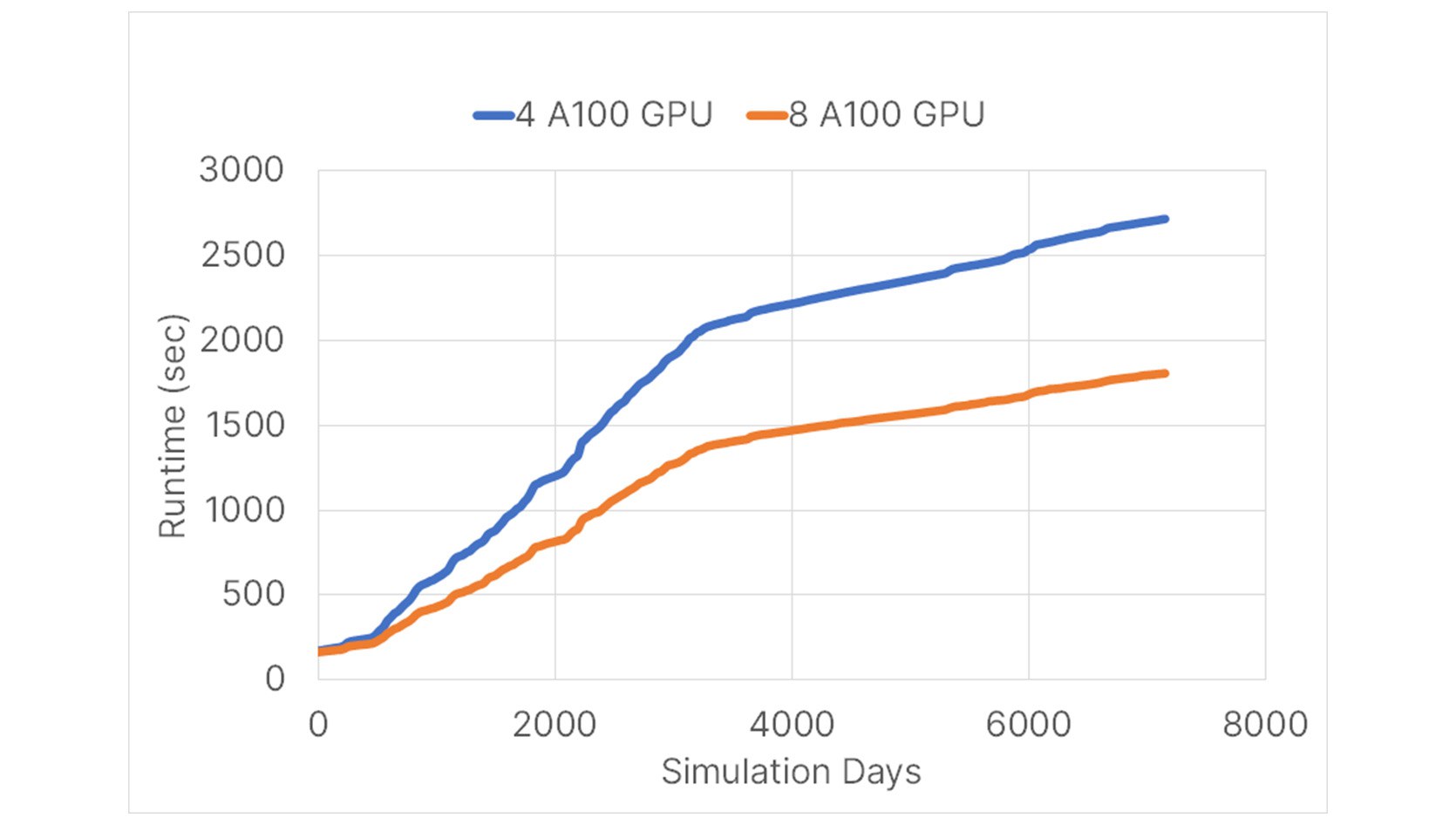
Figure 3 - Simulator runtime of 11.2 million cell test model. 8 GPU (blue) and 4 GPU (orange).
Weak scaling is a measure of parallel efficiency where the problem size and hardware resources are both increased by the same factor. For example, doubling the problem size and doubling the resources under ideal scaling would result in the same runtime. To benchmark simulator throughput and investigate weak scaling with model size we require a model that can be easily extended to larger sizes while preserving the inherent complexity of the physics. We do this by tiling a simple synthetic model in the x-y plane. The tiles are inter-connected, however, by symmetry there should be no flow between them. The base model has 110,700 cells. Testing for this model was done using the new NVIDIA A100 again running ECHELON reservoir simulation software in fully implicit mode (FIM). On 1 GPU we place 4.6M cells, on 2 GPUs 9.3M cells, on 4 GPUs 18.6M cells and on 8 GPUs 37.2M cells. The equation of state includes 6 components. One way to consider performance is to track the throughput of the simulator as measured in cell-simulation days per second. For example, a 1 million cell model simulated over 2000 days in 30 minutes is equivalent to about 1.1M cell-simulation days per second. Figure 4 below displays simulator throughput for the tiled models on 1, 2, 4 and 8 GPUs.
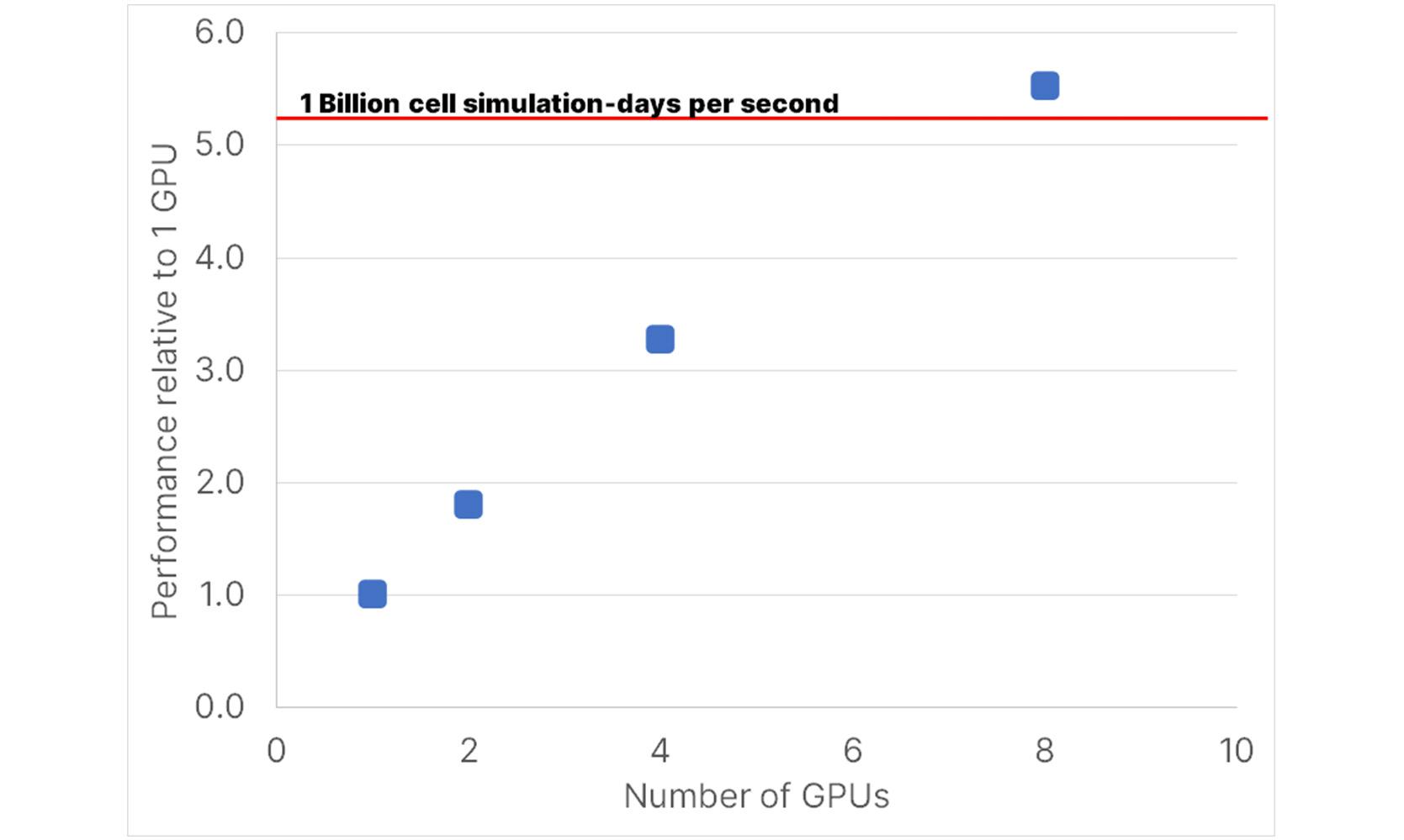
Figure 4 - Tiled model performance millions of cell simulation days per second vs number of GPUs.
The y-axis plots performance relative to a single GPU. Simulator performance ranges from 187M cell simulation days per second on a single GPU to more than 1 billion cell simulation days per second on 8 GPUs. Weak scaling is good with about 90% efficiency going from 1 to 2 and then 2 to 4 GPUs and 85% efficiency going from 4 to 8 GPUs. We also observe that i) the number of linear iterations is nearly constant across the span of these models, demonstrating the optimal properties of multi-grid preconditioners used in ECHELON reservoir simulation software and ii) we are able to fit up to 4.6M cell compositional models on a single GPU.
Strong scaling measures the realized speedup when keeping the problem size constant and increasing the hardware resources. Doubling the number of GPUs applied to a particular model, for example, should ideally halve the runtime. To assess strong scaling we consider the same single GPU base case used for the weak scaling study above and we record runtime on 1, 2, 4 and 8 NVIDIA V100 GPUs keeping model size constant. Note that the NVIDIA A100 was used in the weak scaling study above. Results are shown in Figure 5 below.
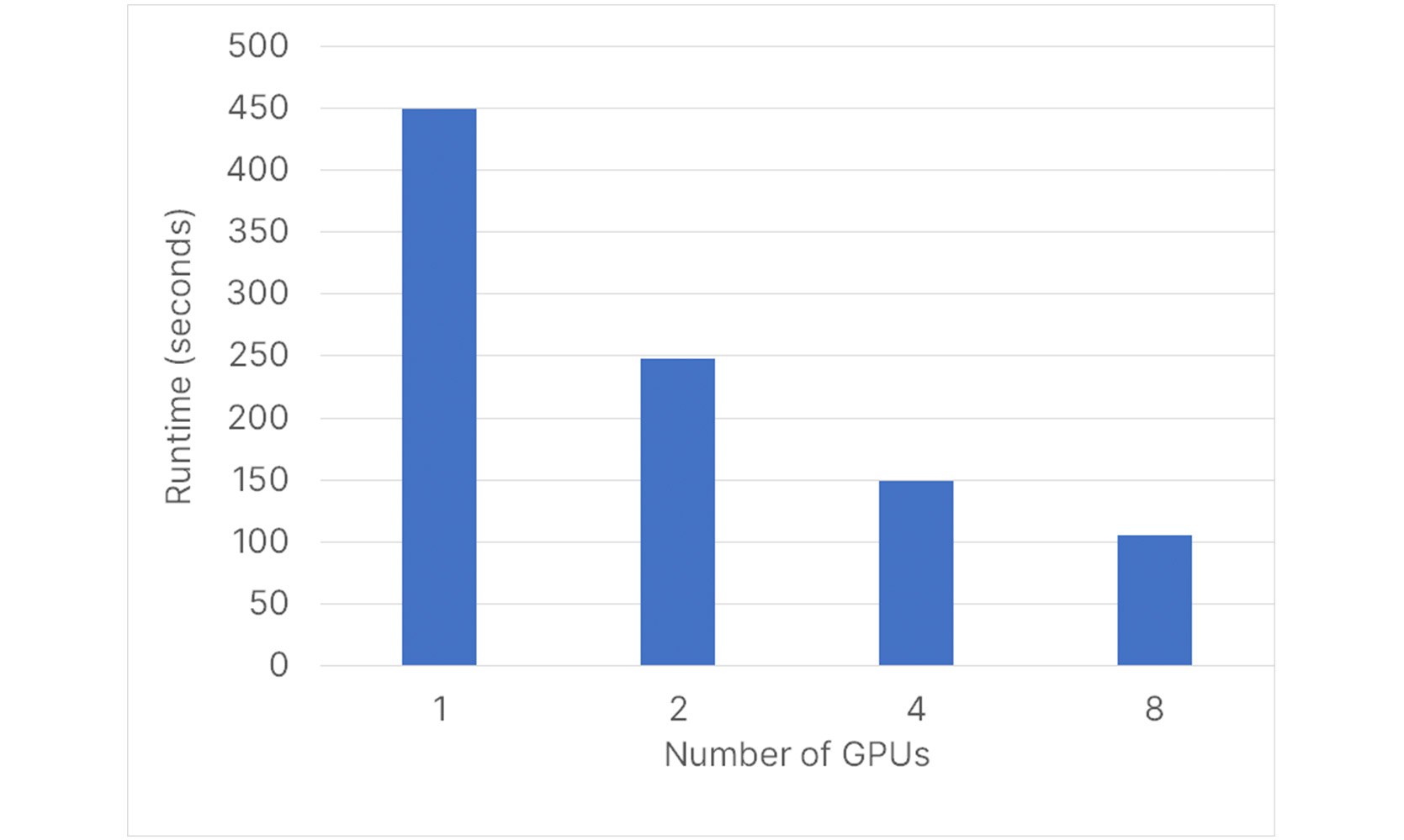
Figure 5 - Strong scaling of 4.6 million cell compositional model from 1 to 8 GPUs.
On a single NVIDIA V100 GPU the model completes in 450 seconds. Going from 1 to 2 GPUs the problem is sped up by a factor of 1.8x for a parallel efficiency of 90%. From 1 to 8 GPUs the problem is sped up by 4.3x for a parallel efficiency of 54%.
Perhaps the most interesting property of ECHELON's compositional formulation is runtime and memory scaling with the number of components. To study scaling with components we began with a base model with about 150K cells. To preserve the physical complexity and yet increase component number we began with a simple 2 component model and successively cloned the components to span a range from 2 to 30 components. Figure 6 (right) displays the runtime per component vs. the number of components. Beyond 10 components we observe that the runtime per component flattens out to a roughly constant value. Each additional component beyond 10 adds about the same computational work to the system.
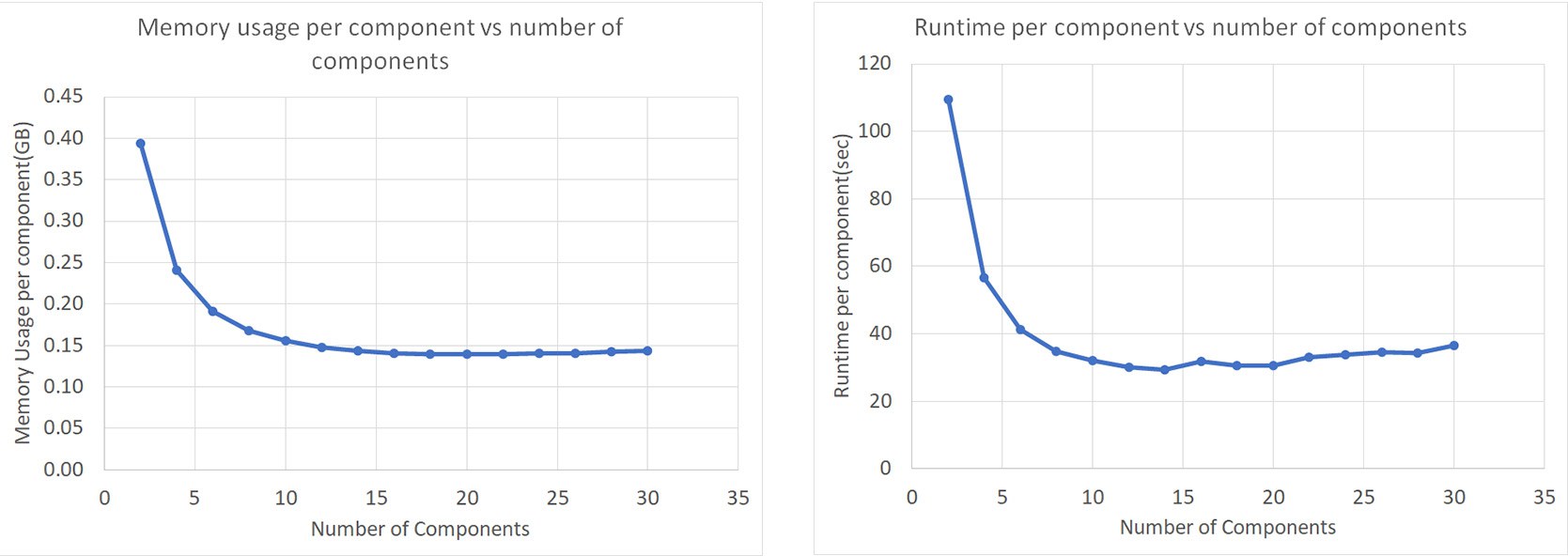
Figure 6 – (Left) Scaling of GPU memory with number of components. (Right) Scaling of compositional model runtime with number of components.
The left plot in Figure 6 displays the GPU memory requirements per component vs. the number of components. All results are recorded using fully implicit methods. Again we observe that beyond 10 components each additional component adds a constant amount (~150MB) to the GPU memory requirements. This comes to about 1KB per cell-component.
ECHELON's compositional formulation sets a new bar for industry performance. An 11.2 million cell model with 9 components is forecast out 20 years in 30 minutes. Both weak and strong scalability are excellent and comparable to what we observe for black oil models. Using fully-implicit (FIM) mode and 6 to 8 components we can fit between 3 and 5 million cells on a single V100 GPU and roughly twice that using adaptive-implicit (AIM). Finally, by design, ECHELON's compositional formulation scales both runtime and memory requirements linearly with respect to the number of components. This feature is unique in the industry and opens up the possibility of simulating large systems with significantly more detailed fluid models. This blog is a brief accounting of a few exciting results. Over the next weeks and months we will present more models, results and details to document ECHELON's performance and scaling for compositional models.

Vincent Natoli
Vincent Natoli is the president and founder of Stone Ridge Technology. He is a computational physicist with 30 years experience in the field of high-performance computing. He holds Bachelors and Masters degrees from MIT, a PhD in Physics from the University of Illinois Urbana-Champaign and a Masters in Technology Management from the Wharton School at the University of Pennsylvania.
