The Exponential Growth of Hardware
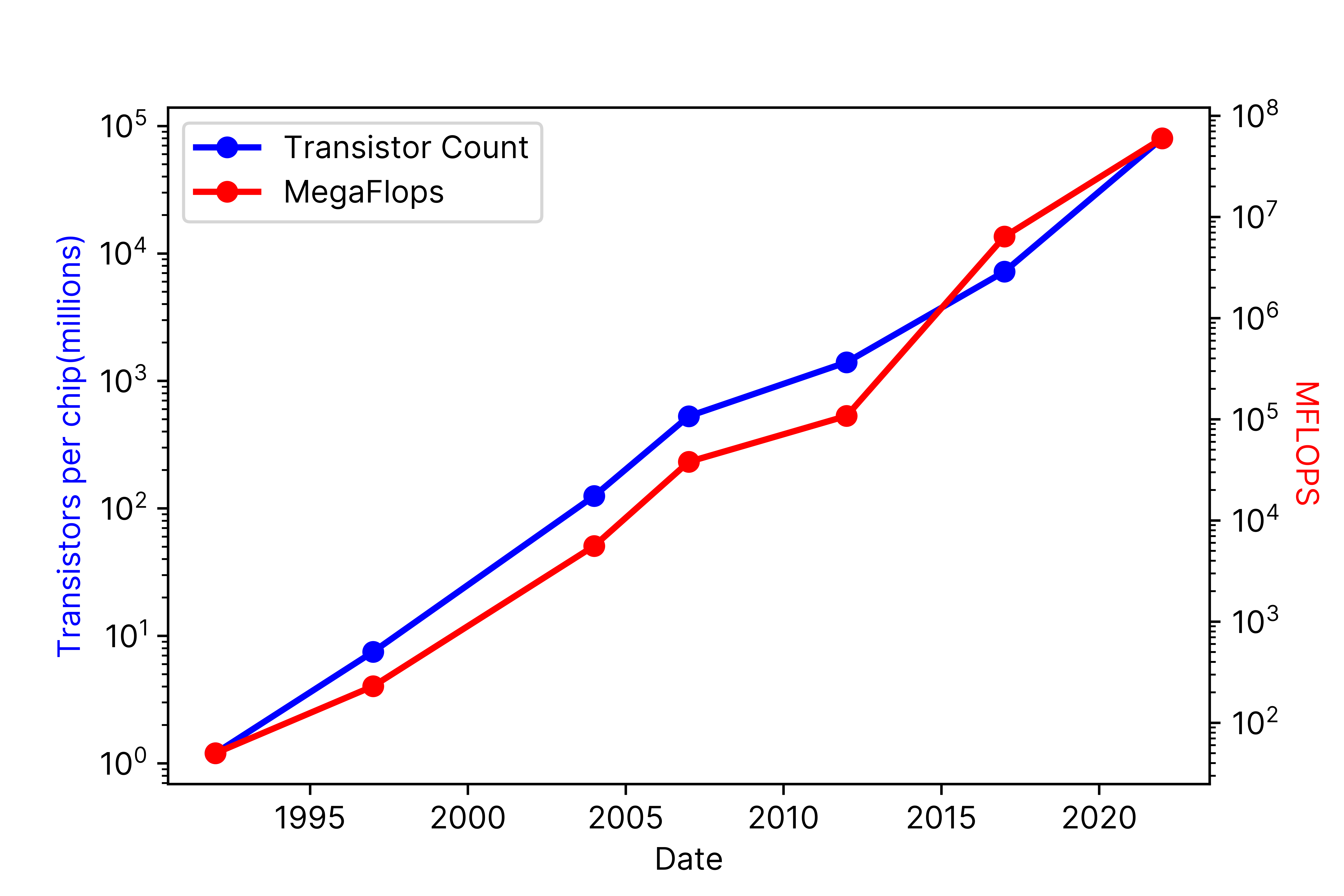
When I finished my Ph.D. in 1992 and began my professional career in computational physics, the Intel 486DX2 was the top-of-the-line CPU. It had 1.2 million transistors and was capable of 50 million floating point operations per second (MegaFLOPS). Thirty years later, we are weeks away from the commercial launch of the NVIDIA Hopper GPU with 80 billion transistors, capable of 67 trillion flops (TeraFLOPS), a 66 thousand-fold increase in transistor count, and a 1.2 million-fold improvement in FLOPS. The exponential growth of these metrics over time (see log graph in Figure 1) is, by now, a well-documented phenomenon; however, it is nonetheless astonishing when viewed from the perspective of three decades.
Figure 1 Transistor count per chip (blue, right) and MFLOPS (red, left) from 1992 to 2022
Three Epochs of HPC Hardware
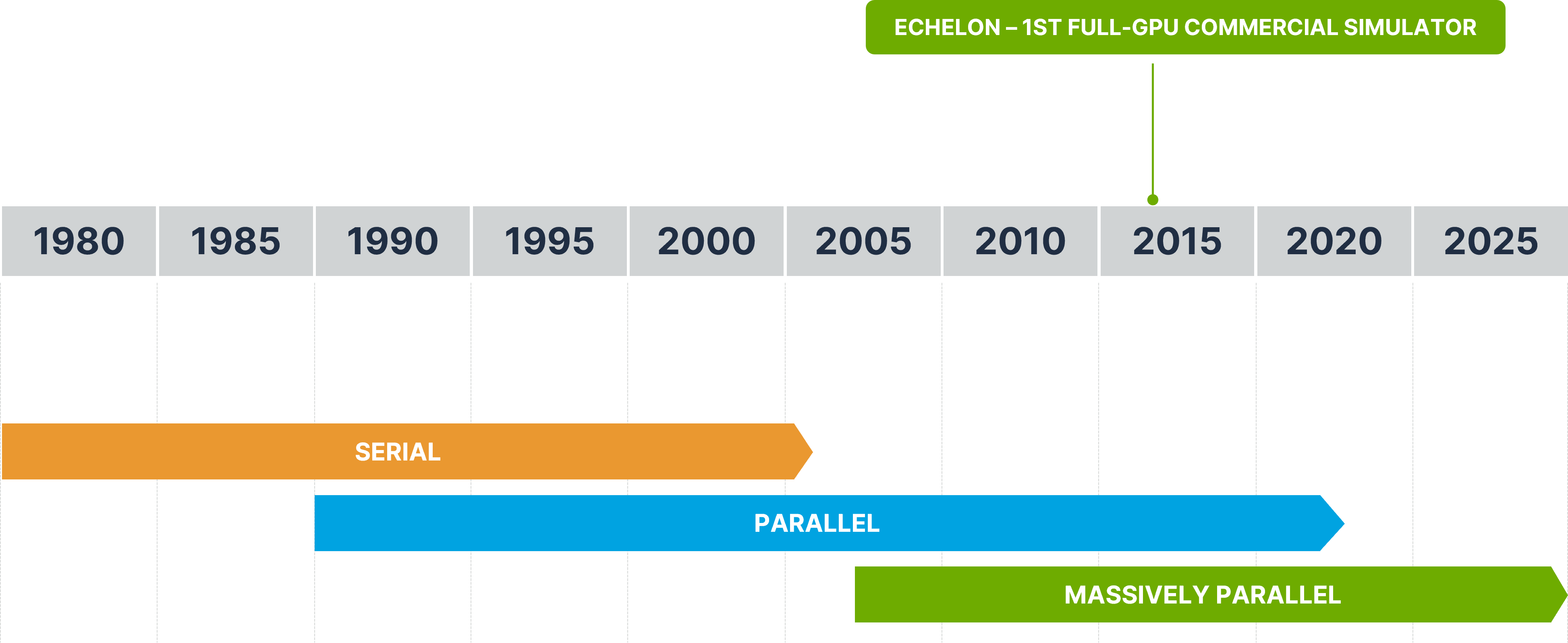
The explosive growth of transistor count has given rise to significant changes in chip architecture and design. I find it helpful to identify three broad overlapping ‘epochs’ covering the preceding 30-year period; the serial epoch, marked by single-core computing, the parallel epoch marked by multi-core computing, and the current massively parallel epoch, marked by computing on massively parallel chips e.g. GPUs (see Figure 2 below). The serial epoch dominated computing from its very beginning until the mid-2000’s. The parallel epoch began when multi-core chips emerged in 2004 as a solution to power and heating issues that dominated at clock speeds above 3GHz. Some years later, NVIDIA initiated the massively parallel epoch when it introduced the general computing community to the GPU and took parallelism to an entirely new level. A key observation is that by introducing first multi-core and then massively parallel architectures, chip designers pushed the problem of application performance squarely into the laps of software developers. If developers want more performance from their code, it’s up to them to figure out how to modify data structures, designs, and most of all, algorithms to take advantage of the new hardware.
Figure 2 The serial, parallel, and massively parallel epochs spanning decades of HPC evolution
The Linear Growth of Software
While computer hardware evolves exponentially, periodically triggering radical changes in design, computer software does not. Software evolves at human speed, changing slowly with time, and relies on the re-use of fundamental building blocks and libraries to build layers of abstraction. The latter is, in fact, encouraged to accelerate development time. If a fundamental change in the underlying hardware occurs, the whole software stack needs to be rewritten - and that takes time. Software evolves as new features and capabilities are added, but the foundations, including the language used, the data structures, and the architecture of the software, change very slowly. This is particularly true of high-performance engineering codes that are used in critical computations ranging from simulating global climate change and analyzing the structural stability of airplanes to applications in the energy industry like simulating the flow of oil, gas, and water in the subsurface or the sequestration of gigatons of carbon dioxide in deep underground reservoirs. Due to their complexity and dependency on optimized mathematical libraries, such applications are known to enjoy extraordinarily long lifetimes. In addition to the immense task of rewriting such software, the results from the new codes need to overlay precisely on legacy results, a challenging task that requires careful analysis of observed deviations. Thus, far from being ‘soft’ or malleable or easily changed, ‘soft’-ware tends to freeze in place like a dated style.
The Productivity Gap
The mismatch between the rate of hardware and software evolution leads to significant inefficiencies, lost productivity, and higher costs. Many software applications in common use today were originally designed for computers that no longer exist, and they have been amended and shoehorned to fit new architectures. Numerous examples exist in our own industry of subsurface simulation. Codes designed for one epoch can be ‘ported’ to the succeeding epoch, but they will be outperformed by codes specifically designed for the new architecture. Clinging to dated software leads to simulation times measured in days instead of minutes, severe limitations on the use of ensemble modeling, where simulations are required on hundreds or thousands of realizations, and often enough, artificial limits imposed on model resolution or the selection and use of more advanced physics, all because codes are just too slow.
In time, as lost productivity mounts and the gap between “what is” and “what could be” becomes wider, the only solution is to rewrite existing applications from scratch, designing specifically for the new modern, highly capable, and complex platform. This is precisely what we have done at Stone Ridge Technology. Our ECHELON reservoir simulator, in contrast to its competitors, was designed from inception for modern GPUs and massively parallel architectures. The data structures, software architecture, and mathematical algorithms were all tailored to execute on massively parallel GPU hardware.
ECHELON is the fastest reservoir simulator in the industry, designed and built for the digital transformation and leading the way to higher productivity, more accurate results, a better understanding of subsurface flow, and improved predictions. If you are not already using ECHELON today, benchmark it for yourself in a trial to see how much performance and productivity you are missing.