ENVOY: An AI assistant for Reservoir Simulation
Generative AI is poised to play a significant role in Reservoir Engineering workflows.

Generative AI is poised to play a significant role in Reservoir Engineering workflows.
Posted in: ECHELON Software SRT AI
Artificial Intelligence (AI) is generating countless opportunities in almost every sector of education, research, the economy, and the arts. Those of us who attended the last NVIDIA GTC conference in San Jose have witnessed how deep and broad the penetration of AI already is. It should therefore be no surprise that AI - and specifically Generative AI (GenAI) - is starting to play a growing role in the energy industry. For those new to generative artificial intelligence, here is an accessible overview crafted by GPT-4, one of the most influential instances of generative AI, as it examines its own capabilities:
”Generative AI refers to a type of artificial intelligence that creates new content, such as text, images, or music, by learning from vast amounts of existing data. Unlike traditional AI, which analyzes and makes decisions based on input, generative AI can produce original outputs by identifying patterns, relationships, and structures in the data it has been trained on. This enables it to generate content that is often indistinguishable from that created by humans, across various domains. It’s a tool that automates the creative process, providing valuable assistance in fields ranging from content creation to design, while always relying on human guidance to ensure relevance and appropriateness.”
GenAI is specialized software running on some of the world’s largest GPU equipped clusters, taking input from users and generating output in response. However, unlike traditional software that is constructed from algorithms that perform very specific tasks such as checking the balance on your bank account, generative AI consists of software that first trains a vast neural network with millions of documents, images, and even music or videos, and then later generates new content in a process called inference when prompted to do so. We call these large trained neural networks Foundation Models or Large Language Models (LLM) and their ”knowledge” is stored in the form of billions of connection weights and node biases inside the network.
In other words, the fundamental architecture and software of these models is similar; what differs is their size, training data, and hyper-parameters used during the training process which result in the defining weights and biases for the network. We can make a rough analogy with the human brain: Its basic structure and volume is very similar among most humans, but education and training, as well as the number of interconnections formed at a young age, plays a crucial role in developing one’s particular knowledge and skills.
In that context, we want to emphasize the importance of the requirement mentioned by GPT-4 in the last sentence: ”...while always relying on human guidance to ensure relevance and appropriateness”. Put in simple words, the quality of the input determines the quality of the output. This does not just apply to the training of the network, but is of equal importance when prompting it to generate new output. The above explanation of GenAI by GPT-4 for instance was generated based on a prompt that gave detailed instructions about the target audience and the expected depth and length of the explanation. To illustrate that further, assume we prompt GPT-4 to explain GenAI to a five year old. In that case, the answer is:
”Generative AI is like a magic art box that can draw pictures, write stories, or make music all by itself, but it learns to do so by looking at lots of art, stories, and music that people have already made. It’s like having a robot friend who can create cool things, but it needs to learn from what you show it!”
As the two examples show, a LLM can generate vastly different answers depending on the instructions we give it. Formulating one's questions and demands in the correct way (based on the purpose) is known as prompt engineering. We will come back to this later.
Ever since the advent of GPT and its web interface ChatGPT, people have marveled about the abilities of generative AI. College students have (ab)used it to write their essays, employees use it to write their resumes, customer support workers have used it to generate replies to product related questions, and lawyers have used it to write pleas - sometimes to the amusement of the public when it turned out that citations to cases were entirely fictitious. Some of the more humorous examples of use demonstrate a misunderstanding of GenAI’s capabilities. As stated before, GenAI is about creating new content from existing content in a way that is often indistinguishable from human created responses. This does not imply an intrinsic understanding of the content - only the ability to detect patterns, structures, and relationship between words and symbols. If a model has been trained using one hundred educational math books at graduate level, then it will most likely be able to teach you how to integrate a polynomial. It will not have an intrinsic understanding of the mathematics behind it, but it will combine and summarize its learning, and stream out words and sentences that makes us believe it knows what it is talking about - even if it doesn’t. This process of creating new content from learned examples sometimes works a bit too well (as in the case where a lawyer used GPT-4 to write a plea), leading to model responses that are simply plain wrong and/or fictitious. Experts call this hallucinating and it is one problem we have to be aware of when using Generative AI for our purposes.
Apart from the fact that even the latest models sometimes give wrong answers with a convincing level of confidence and detail, GenAI has shown remarkable abilities to digest large data sets, summarize their content, point out relationships, and draw conclusions based on input prompts. This has spurred companies to make fundamental changes to the way they work with documents and information. Instead of building tools to retrieve data, they now build tools to generate information from existing data. We can think of the following analogy: In the 1950s, an employee would have gone into the company archives to retrieve some dusty binders with research documents or construction plans. In the 1970s, the documents were all transferred onto microfiche and could be read with a viewer. In the year 2000, an employee would have pulled the documents from a database and studied them on a computer screen. Today, with the help of GenAI, an employee can ask the computer to generate a list of materials that were used in the construction of a device whose construction plans were digested by the system. He may then ask for the material cost based on today’s prices. This is new information that cannot simply be retrieved. It has to be generated. GenAI will transform the way we work with data, transitioning from improving the ways we retrieve data towards generating new information from it.
Before we dive into Stone Ridge Technology’s latest development efforts in Generative AI, we need a little background on how tools like ChatGPT, Microsoft Co-Pilot, and chatbots in general work, that is, we will focus on the front-end application and not the LLM. Readers who follow our blog (PINN blog) may have read our article about physics informed neural networks (PINNs) that gave a short introduction into the basic structure of neural network architectures at the beginning of the article. Here, we will just say that behind tools like ChatGPT or Microsoft Co-Pilot, there are very large networks that have billions of neural interconnections and whose weights have been trained by digesting millions and millions of documents from the internet - a single complete training incurs costs in the range of millions of US dollars. The tools that interface with them are called chatbots or co-pilots. Hence, ChatGPT is a web-based front-end application that talks to a large foundation model like GPT3.5 or GPT4.0 as sketched in the figure below.
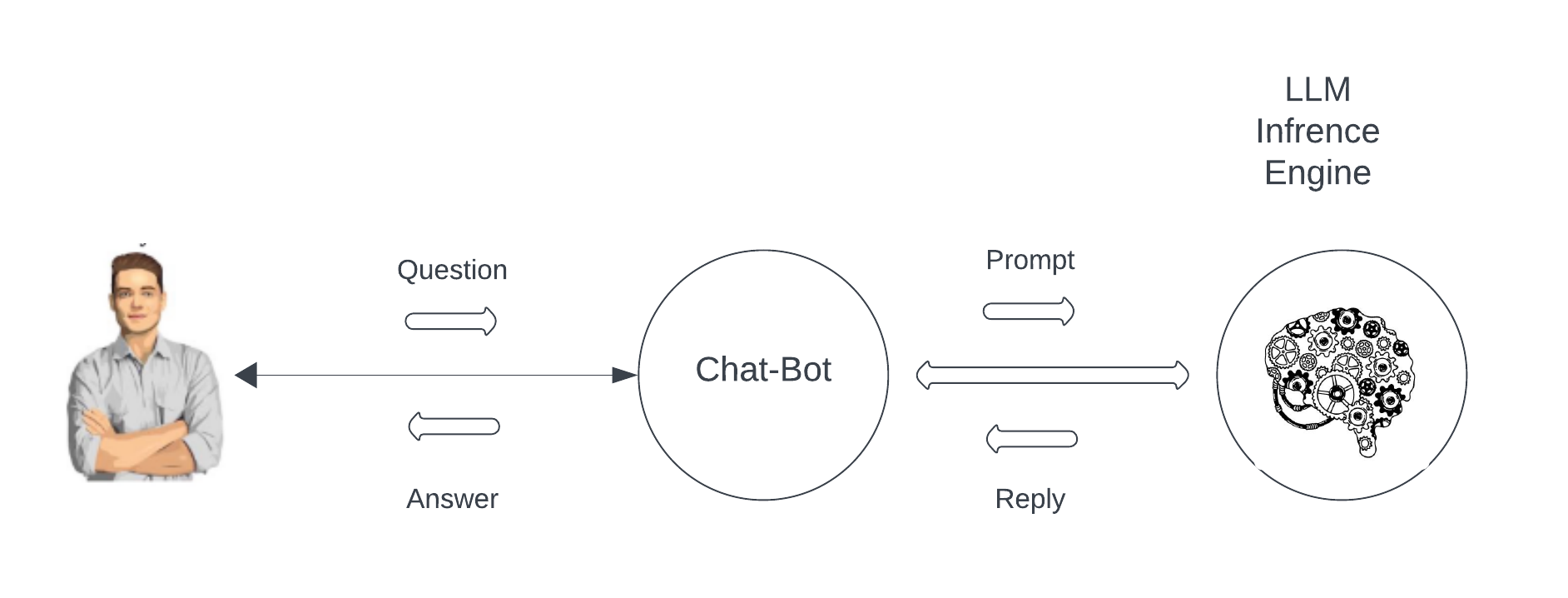
So, how can we at Stone Ridge Technology take advantage of the vast ”knowledge” of foundation models for the benefit of our clients? On the one hand, these models have digested probably 80% of all digitized knowledge that humans have created and, therefore, are able to uphold conversations over a wide range of interests in multiple languages - surpassing in complexity and richness any dialog that the programmer of a dedicated chatbot application could possibly create. On the other hand, these foundation models have probably never heard of ECHELON, the fastest reservoir simulator in the world, built from inception for GPUs, and will fail to answer any detailed questions about it. Re-training or fine-tuning a large foundation model is out of the question due to the costs involved. An alternative is to take a much smaller model and fine tune it for reservoir simulation and ECHELON, however, we then lose the ability to communicate in multiple languages and also lose many of the advanced ”reasoning” capabilities that make these models so fascinating and useful in the first place.
One solution is to use what is called Retrieval Augmented Generation or RAG. Before we explain what this means, a quick clarification or reminder on how we interact with LLMs. Large language or foundation models are static neural networks occupying vast computational servers. They interact with hundreds of thousands or maybe millions of users at any given time, processing millions of requests in parallel. An input prompt is received and triggers a response. It should be clear that there is no learning involved in such conversations, and that no memory of a conversation can be kept. The same electronic circuits that just generated a recipe for a traditional apple pie will generate an answer related to a question in quantum physics a fraction of a millisecond later.
So, how is it possible to have a conversation with such a model? The answer is that the chatbot used to communicate with the LLM keeps a history of the conversation, and each time we enter another sentence or prompt, the entire conversation history (growing linearly in size) is fed to the model together with our next prompt. In that sense, the chatbot is like a parrot, repeating a growing conversation history over and over again in its communication with the network that responds to each prompt of a linearly growing input - giving us the impression that it is able to uphold a conversation. Since the latest LLMs are able to process tens of thousands of words in a single prompt, such conversations can become quite long before amnesia sets in.
Here is an illustration of how its works:

We can use this mechanism to our advantage and inject additional information into the communication stream without the user seeing it - similar to how we add the chat history to each prompt. We call this augmenting the prompt or augmented retrieval. Following is a trivial example of how a conversation with augmented retrieval may proceed.

Now, it almost looks like cheating. We basically give the answer to the model and it parrots it back. Why bother to involve the model then? Well, even in this simple example we can save a lot of programming work by not having to parse and understand the user’s question ourselves but let the LLM do the work. Just assume for example that Frank types the following question: ”I feel sick today but don’t know if I should take off”. That’s not easy to anticipate and if we are responsible for analyzing the text we have to put a lot of effort in our parser. The LLM can handle questions like that easily and maybe respond to Frank that he has enough paid sick days left, and that in order to protect his coworkers he should stay home if he feels sick. It can also remind him to inform his supervisor. In the example above, the chatbot looked up Frank’s vacation and sick-day records from the employee database and simply gave all information to the LLM, together with Frank’s question. The figure below sketches the RAG process.
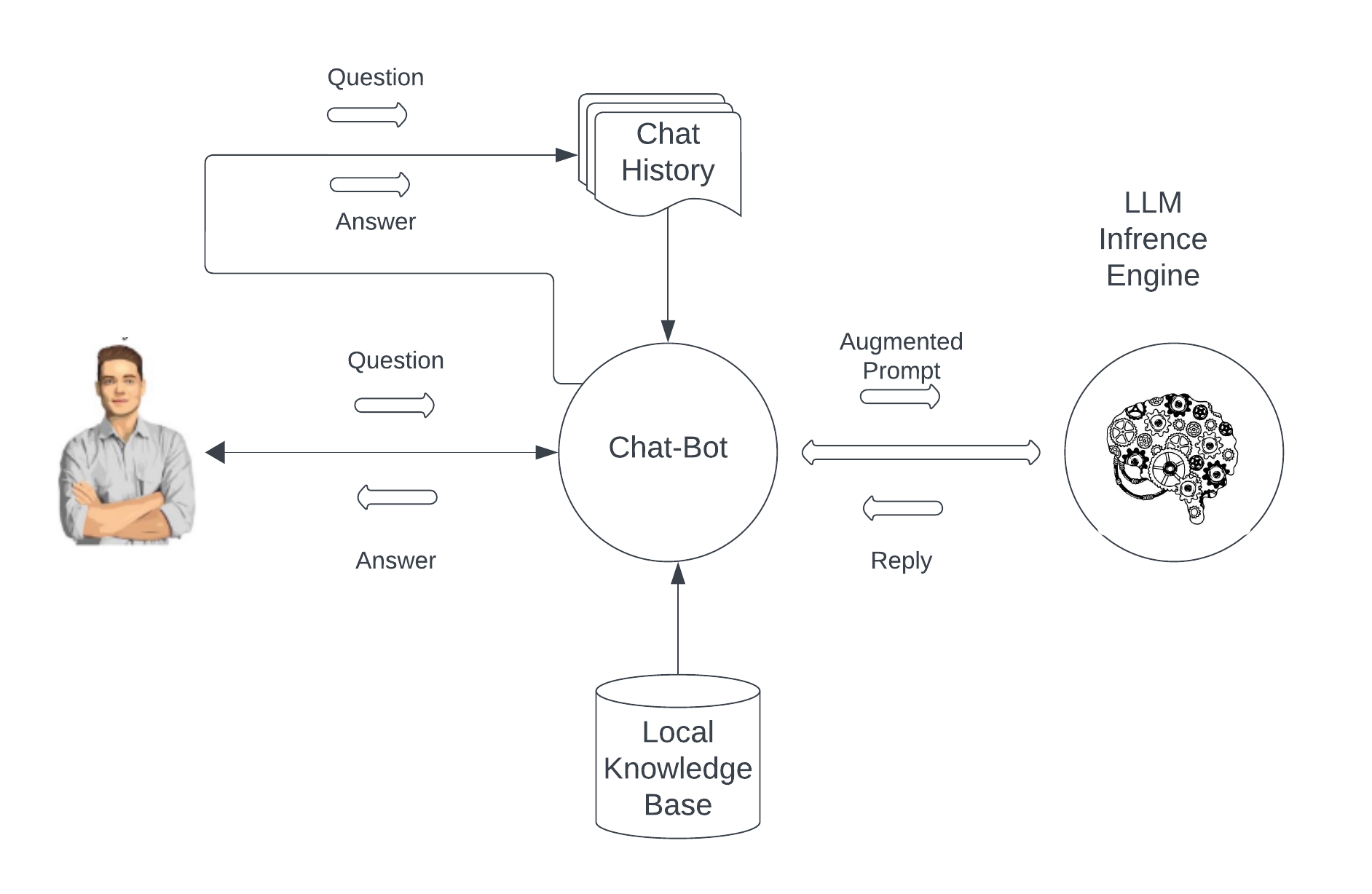
Let us now proceed to the heart of the blog article, but before we talk about the AI work at Stone Ridge Technology, consider the idea of building a RAG-based chatbot that answers questions about our flagship product ECHELON. We clearly need a RAG process to feed the necessary context information to a large LLM - unless we want to spend the money and train or fine tune a model by ourselves. Since we can hardly anticipate all possible questions a user or potential client may ask, we look around and collect all relevant technical documents, reference and training manuals, and even information from our website and store it into a database. However, this is not a typical relational database which requires us to build a schema and select keys - something that’s hard to do if you just have a vast trove of unstructured documents. Instead we store it in a special form of database that allows us to perform what is called a similarity search. We explain this later, for the moment just assume that by passing a query in the form of a sentence or question, the database responds with sentences and paragraphs (many of them) that somehow relate to words found in the question. So, if we ask the question ”How do I specify the number of hydrocarbon components in ECHELON?” Our database will respond by returning a slew of mini documents with fragments from the user manual, the reference manual, training documents, etc. - anything that somehow relates to ”hydrocarbon”, ”component”, ”specify”, ”ECHELON”, etc. If we would simply report this back to the user, they would be rather disappointed. But if we provide all this information as additional context to the LLM together with the original question, the awesome powers of GenAI and its ability to summarize and contextualize information will generate an almost perfect answer. So, how does this similarity search work? Here is a very brief answer within the scope of this blog article:
Consider measuring the distance between 2 points in a 3D Euclidean space. You square the individual coordinate differences, add them up, and take the square root. You can do that also in a 1024 dimensional space - it's just more work. It allows us to define how ”close” points are to each other. If we want to do the same with words, we can convert them to vectors of numbers, but the conversion has to somehow reflect a variety of meanings. For instance, the words ”distance” and ”length” should be close but ”distance” and ”estranged” should be close too, because two people can be distant from each other in an emotional sense. Converting words into number vectors to reflect closeness based on the many possible interpretations and technical, geographic, or social considerations requires more than just one dimension. In fact, it requires thousands of dimensions and the conversion itself requires the use of a large language model. A bootstrapping process so to speak. We call these transformations Embeddings and they are the ”secret sauce” to our database that allows similarity searches. Since we are dealing with vectors of numbers, the database is called a vector store.

So, here is what we do. We split all our documents and website information and everything we can find about ECHELON into smaller paragraphs and use embeddings to translate all information into a vast number of vectors and store them into a vector store database. Whenever we have the user asking a question, we convert the question into a set of vectors and perform a similarity search (which could be as simple as Euclidean distance) and return the sentences and paragraphs that are close to our question in the embedding space. We give all of this to the LLM which will (hopefully) sort things out and give a reasonable answer. Our team here at Stone Ridge Technology has already successfully built a prototype of a RAG based simulation assistant that we have given the name ENVOY. It works very well in answering questions about the simulator and its required input, as well as answering questions about numerical reservoir simulation in general.
At Stone Ridge Technology, we realized early on the potential of AI and machine learning in reservoir simulation as we indicated in our blog article from last year about physics informed neural networks and potential applications in reservoir simulation and Carbon sequestration. Since then, research and development work has followed two directions. One is the development of an integrated physics based machine learning environment for history matching and production optimization with ECHELON in its center, and the other is the development of a GenAI based intelligent simulation assistant or co-pilot called ENVOY.
Quoting one of our colleagues who is currently helping a client to convert simulation models from a legacy simulator to ECHELON:
”You spend one hour to generate the input deck and then ten days to edit It. Most of my work is looking through existing input files and making small changes here and there, interrupted by running the model to test my changes.”
Working with input files that contain hundreds of keywords, many of them having multiple records that by themselves contain various fields, is frustrating for both experts and novices. The expert sees his time wasted by searching through and editing files, while the beginner has to go forth and back between the files and simulator manuals because of unfamiliarity with the keywords and their syntax. Often it is not even clear which keyword to use. Having access to a GenAI-based assistant that answers questions about the simulator and its input files and is able to generate file content is extremely valuable and time saving. Below are some examples of interactive conversations with ENVOY.
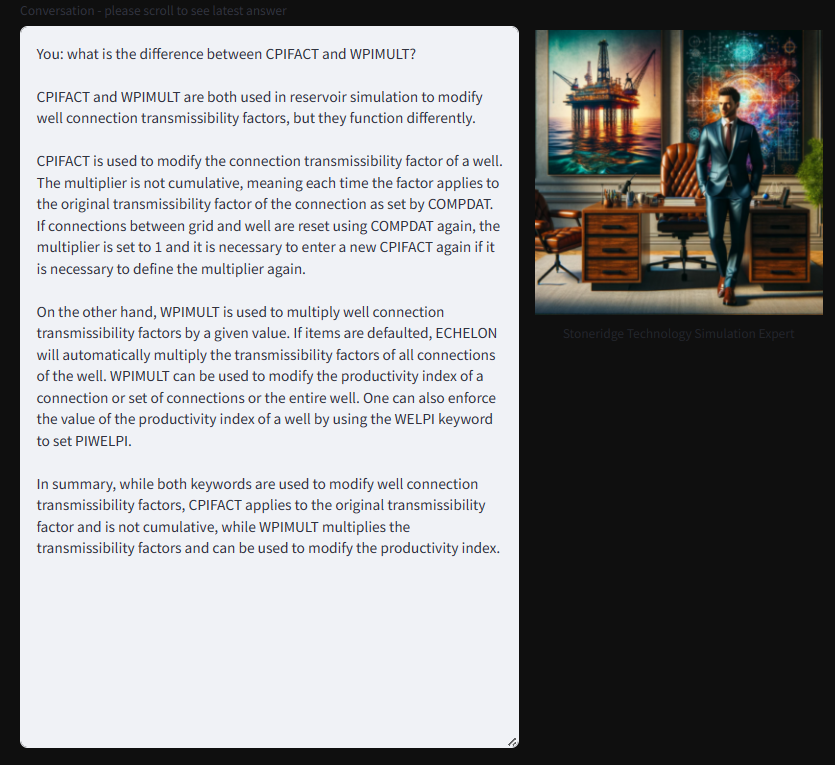
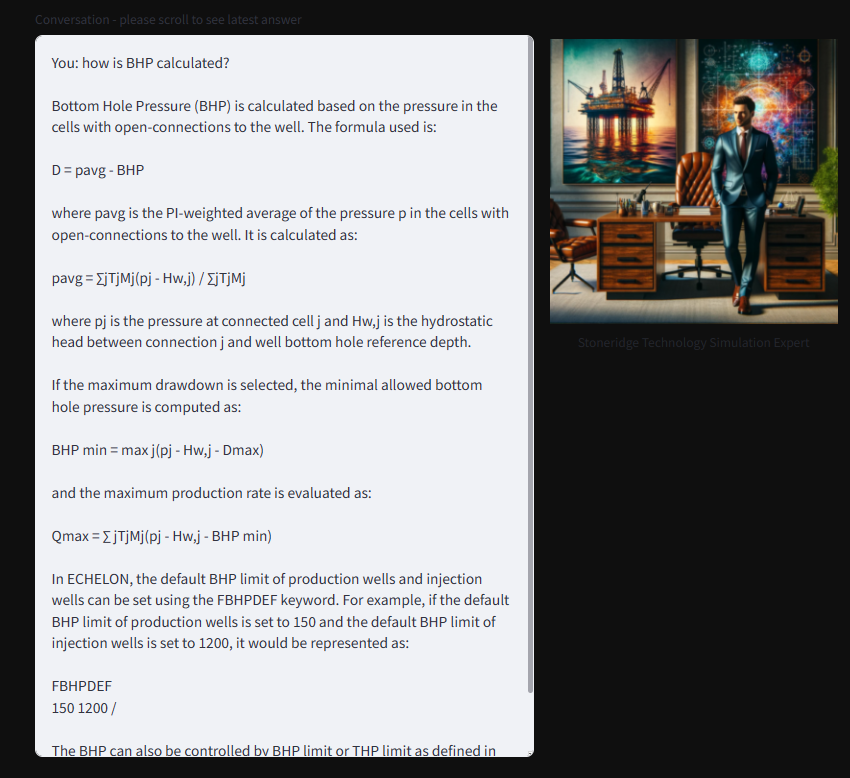
Taking the idea a step further, the simulation assistant can also be used to analyze simulator input files as well as output files generated by the simulation engine, answering questions about the simulation model and giving advice on how to improve it. However, this is where standard RAG technology hits its limits. ENVOY makes use of three mechanisms to accomplish this more advanced task: Agents, Prompt Rephrasing, and Callbacks
Agents
A set of programs and scripts that we call analyzing agents parse the input and output files of simulation models and enter a summary of key insights, performance indicators, and extracted features into a database or vector store. For example, we record the number of cells, active cells, layers, the type of simulation model, the length and dates of the historic production/injection and forecast periods, the number of wells, the well schedules, and so forth and store this into a model knowledge database or vector store.
Prompt Rephrasing
While the information is readily available once we perform the right database or similarity query, it is less accessible to questions such as ”How big is the reservoir?” or ”How large of a model is it?”. Even a similarity search will only pick up partial information if imprecise questions are asked by the user. Therefore, Envoy passes the question to the LLM together with contextual information, prompting it to rephrase the question. The application then uses the rephrased question to query the vector store or database and then formulates a prompt together with the newly discovered context and passes this to the LLM for an answer.
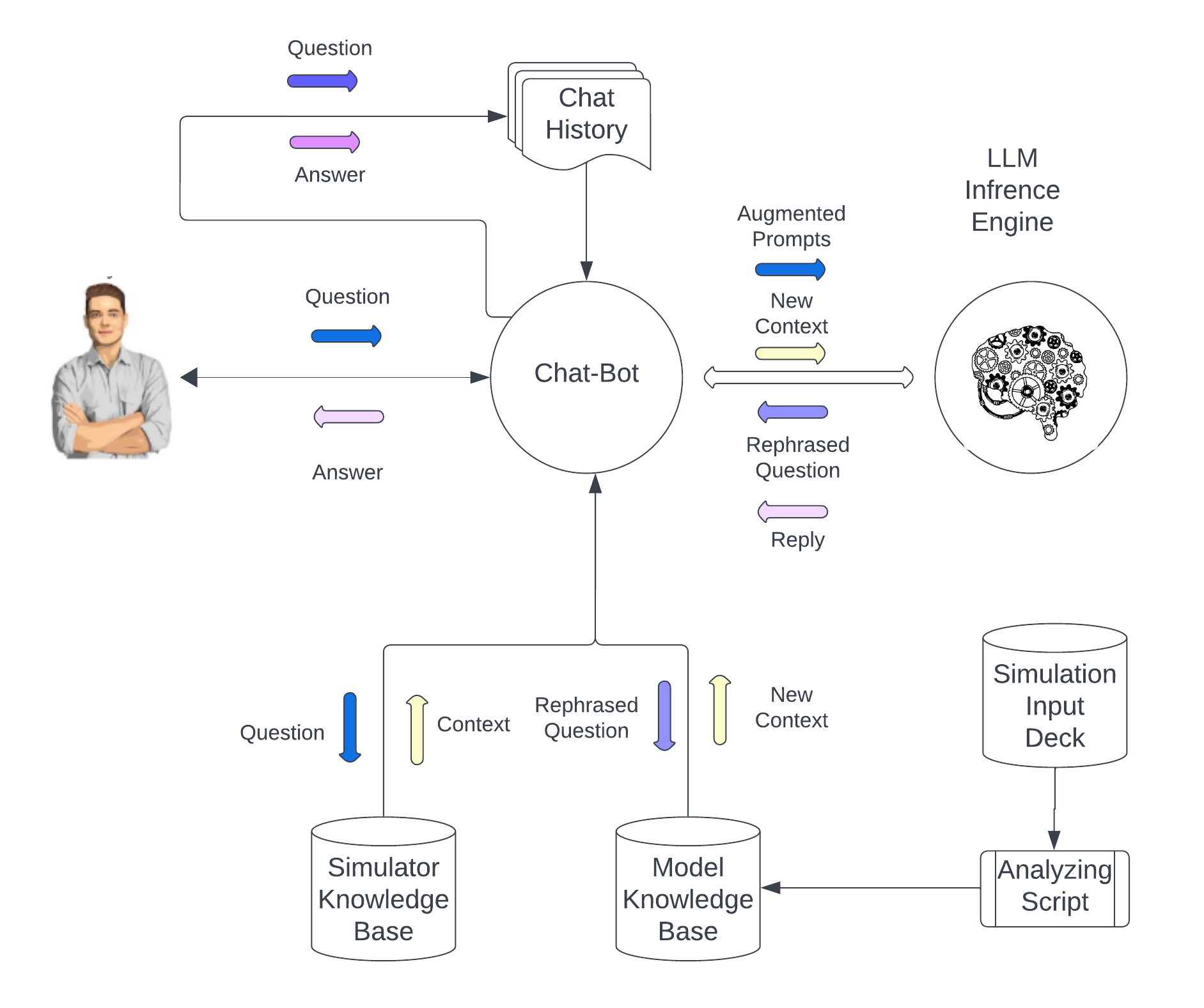
Callbacks
Besides the use of analyzing agents and prompt reprhasing, ENVOY also uses model callbacks, a relatively new technique introduced by the Claude model from Anthropic. The LLM that is being executed on a remote GPU cluster is of course unable to directly invoke local functions, but we can instruct and inform the model about available callback functions, their purpose, and their signature, and perform the function call locally inside the chatbot if asked by the LLM to do so. It is similar to rephrasing questions in the sense that the entire conversation together with the result of the function call is communicated back to the LLM in order to receive either the final answer or a request for another callback.
A good example of using callbacks is a function that allows the user to ask for statistical properties of input and output data - something we can hardly compute upfront due to the combinatorial explosion of possible queries. So, when a user asks ”What is the average porosity in layer 5?” or ”What is the minimum and maximum bottom hole pressure of well producer_5 during the first two years of the simulation?”, then we pass the question to the LLM together with a list of functions that can be used, and expect the model to come back to us, requesting the invocation of one or more callback functions. Intelligently designed, we can even drop part of the intermediate history in the ongoing conversation in order to reduce the number of input tokens and cost while the user proceeds with more questions. Figure 6 shows the kernel architecture of ENVOY, using both analyzing agents and callback functions to analyze model inputs and outputs.
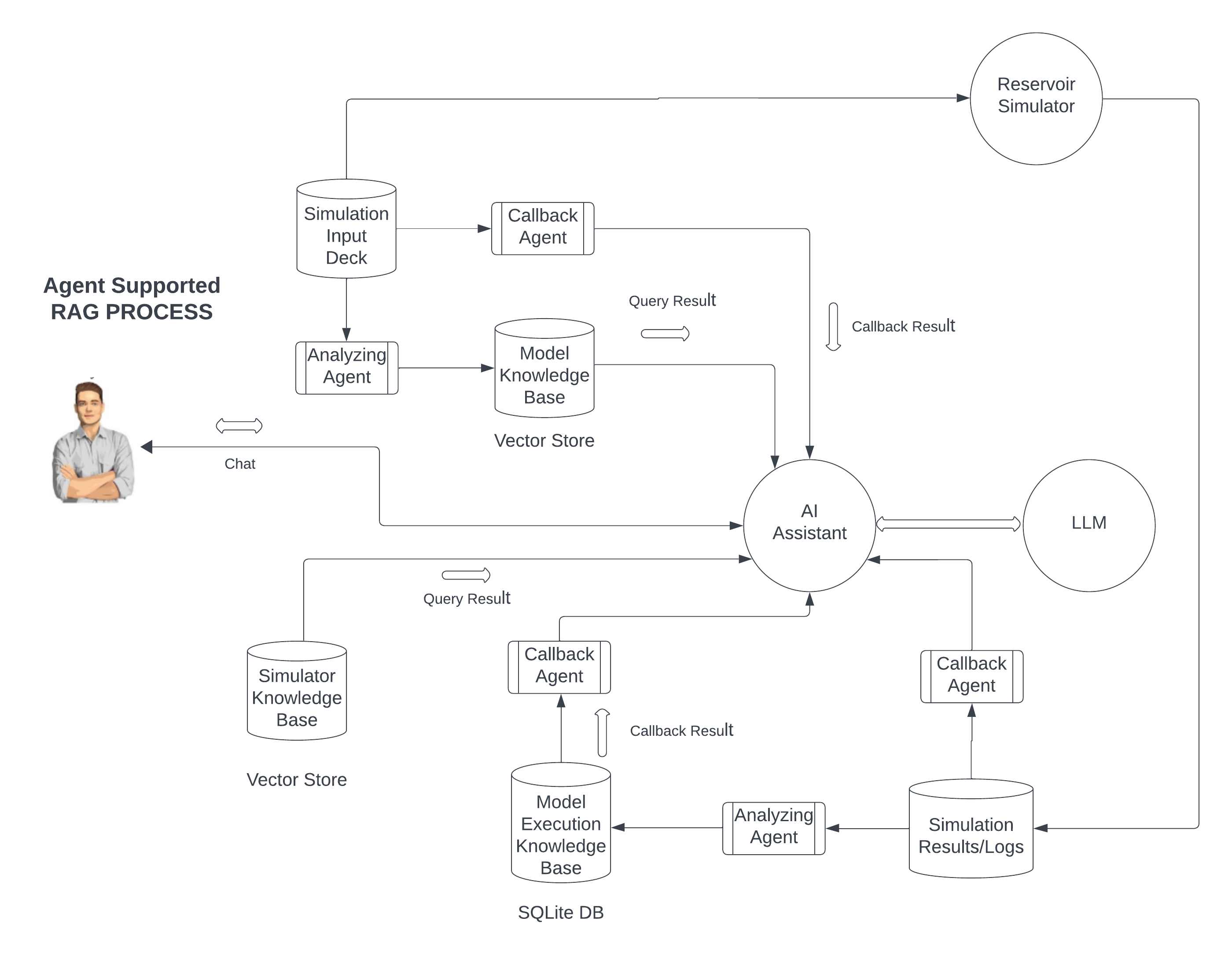
Stone Ridge Technology partners with Amazon Web Services (AWS) to build an integrated cloud solution for creating, executing, and analyzing reservoir simulation models by pairing ECHELON and Envoy with Amazon Bedrock and Anthropic Claude. AWS Bedrock, a fully managed service for building and deploying machine learning models, provides a robust environment for hosting and serving the assistant’s AI components, while the AWS cloud computing and storage services - providing EC2 instances and S3 storage management - together with their role-based access models provide a safe, efficient, and scalable execution environment for the ultra-fast ECHELON simulator. Presently, we are co-developing workflows that will allow clients to drop models into S3 storage buckets, triggering the automatic execution of agents to analyze and eventually execute the model with the ECHELON simulator. ENVOY is part of the workflow, allowing the user to interrogate the model and its simulation results.
Stone Ridge Technology plans to roll out the Envoy prototype to selected and interested clients in the near future. Access to the intelligent assistant will be free of charge to early adopter beta testers. We believe that early feedback from our customers will enable us to develop a better final product that truly meets the needs of the reservoir simulation community. If you are currently an ECHELON customer and would like to beta test ENVOY please contact us today at envoy@stoneridgetechnology.com!


Klaus Wiegand
Klaus Wiegand is Senior Scientific Advisor at Stone Ridge Technology. Prior to joining SRT Klaus developed numerical reservoir simulation software at ExxonMobil where he spent 22 years. Klaus has a Masters degree in Computational and Applied Math from Rice University.

Karthik Mukundakrishnan
Dr. Mukundakrishnan is the Director of Research and Development at Stone Ridge Technology. Prior to joining Stone Ridge Technology, he was a R&D Technology Manager at Dassault Systemes Simulia (formerly ABAQUS Inc.). He has more than 15 years of experience working on HPC codes and published extensively in the areas of fluid dynamics, multiphysics coupling, and reservoir simulation. Dr. Mukundakrishnan obtained his M.S. and Ph.D. in Mechanical Engineering and Applied Mechanics from the University of Pennsylvania.

Mahmoud Bedewi
Mahmoud Bedewi is a Reservoir Engineer at Stone Ridge Technology with 18 years of experience in the Oil & Gas industry mainly in Reservoir Simulation including advising major IOCs and NOCs around the globe, Mahmoud has a MSc Degree with distinction from Heriot Watt University in the United Kingdom

Dan Kahn
Dan specializes in HPC at AWS Energy with a focus on spearheading digital transformation initiatives for global energy companies. With two decades of experience innovating in subsurface property studies, Dan's expertise spans across multiple sectors from geophysics to performance computing. Holding a Ph.D. from Duke University, Dan combines academic rigor with practical innovation to drive impactful change in the HPC domain.

Dmitriy Tishechkin
Dmitriy Tishechkin is Partner Technical Lead for Energy at AWS. He leads Energy digital transition efforts by enabling software vendors with latest cloud technologies. Dmitriy effectively combines domain, business, and technology knowledge and experience to accelerate Energy workflows and deliver value to customers

Vidya Ananthan
Vidyasagar specializes in high performance computing, numerical simulations, optimization techniques and software development across industrial and academic environments. At AWS, Vidyasagar is a Senior Solutions Architect developing predictive models, generative AI and simulation technologies. Vidyasagar has a PhD from the California Institute of Technology.
