High Performance Computing Trends: Core Issues
The only way to achieve performance on modern processors is through deliberate design that makes effective use of massive on-chip parallelism.

The only way to achieve performance on modern processors is through deliberate design that makes effective use of massive on-chip parallelism.
Posted in: High Performance Computing
The key observation here is that the only way to achieve performance on modern processors is through deliberate design that makes effective use of massive on-chip parallelism
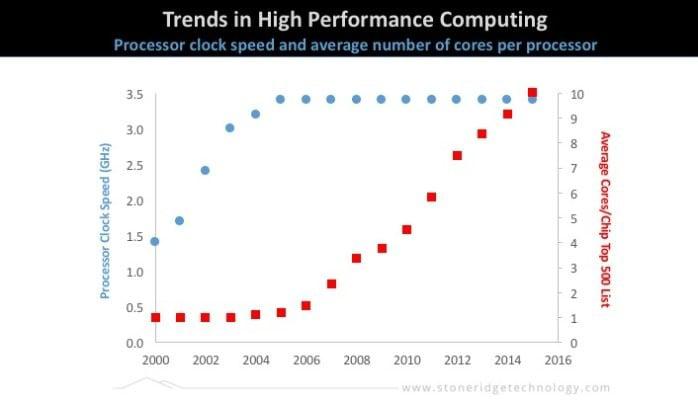
The figure above displays processor clock speed(left) and average number of cores per processor(right) over the last 15 years. By now this is a familiar story, but I want to go a little further and try to extrapolate its implications for software development. CPU clock speeds saturated in the mid 2000’s, almost 10 years ago now. Prior to 2005 clock speed reliably increased each year and our applications became faster with each new hardware generation. However power dissipation which is proportional to the square of the clock frequency prevented further gains past about 3.0Ghz. In fact if you explore a retail site today e.g. newegg.com you will find chip speeds between about 1.8 and 3.7 GHz which is just about where things were in 2005. The feature size on the chip continued to shrink as per Moore's law so if not to give us more speed then what did designers do with the additional space? They put more functionality onto the processor including things like encryption, decryption, network processing, video encoding and more sophisticated logic but the main thing designers did with the additional real estate was to put more computing cores on the processor. First two, then four and by now you can get chips with up to 16 cores.
Our approach to parallelism in scientific computing has been to employ a coarse grained decomposition where we divide the simulation grid into N pieces and distribute those pieces on computational elements using either MPI or a threading protocol like OpenMP or pThreads. But there are drawbacks to this approach in the world of many core parallelism. Mainly they require the user to explicitly orchestrate the movement of data between domains and they can be very heavyweight for what we are trying to accomplish. For example, consider MPI. Whereas it makes sense to communicate with MPI between nodes of a cluster it does not make sense to do so between thousands of cores on a single processor. Even threading approaches, while lighter weight than MPI are heavy for this purpose. One of the problems with any approach based on domain decomposition is that as we decompose our problem over more and more cores our domains get smaller and smaller. Consequently there is less calculating done in each domain and there is more communication between domains. The ratio of compute to communication becomes unfavorable. GPU programming models provide an alternate approach that maps more naturally to many core parallelism. This should not be too surprising as GPUs with the main task of rendering millions of independent pixels on your computer screen every 60th of a second or so have evolved to do this task efficiently with many cores. Modern GPUs already present thousands of cores to the user and task scheduling and data communication is accomplished in hardware at a very low level. There can still be a domain decomposition layer using MPI between GPUs however the domains are much bigger so the compute to communicate ratio is more favorable.
The key observation here is that the only way to achieve performance on modern processors is through deliberate design that makes effective use of massive on chip parallelism. This is true whether you are using CPUs or GPUs. There is no near future scenario where our hardware is delivered with fewer cores. To design software that will scale with these architectures we must think from inception about algorithms and approaches that support thousands of independent threads of work.
This post is one of several based on themes I presented in a keynote talk delivered in mid-September 2015 at the 2nd annual EAGE workshop on High Performance Computing in the Upstream in Dubai.

Vincent Natoli
Vincent Natoli is the president and founder of Stone Ridge Technology. He is a computational physicist with 30 years experience in the field of high-performance computing. He holds Bachelors and Masters degrees from MIT, a PhD in Physics from the University of Illinois Urbana-Champaign and a Masters in Technology Management from the Wharton School at the University of Pennsylvania.
